Field entry, 6 May.
The problem with ordinary agent search is not that it fails to find things. It usually finds something, which is worse in the small tragic way software likes to be worse.
One query goes out. A handful of plausible pages come back. The agent reads just enough to feel oriented, then begins to write with the confidence of someone who has mistaken a street corner for a city survey. For simple questions this is fine. For anything with moving parts, conflicting claims, product nuance, source quality, blocked pages, stale summaries, and vendor documentation written by committees with access to coffee and legal review, it is not research. It is a search result wearing a blazer.
Deep Research started from that annoyance.
I wanted Atlas to have a mode that made the agent work harder in the right direction: search wider, read more deliberately, keep track of evidence, notice where sources disagree, and spend enough time synthesizing that the final answer felt like a memo rather than a confident paragraph with decorative links attached.
The small product surface was important. I did not want a new research cathedral hiding behind three setup screens. The composer needed to stay simple: attach files, or research. A user writes the question, arms research, and Atlas treats the turn differently. That sounds like a UI detail, but it is actually the boundary of the whole feature. Research should feel like a mode of the conversation, not like being handed off to another application with a clipboard and a faintly superior expression.
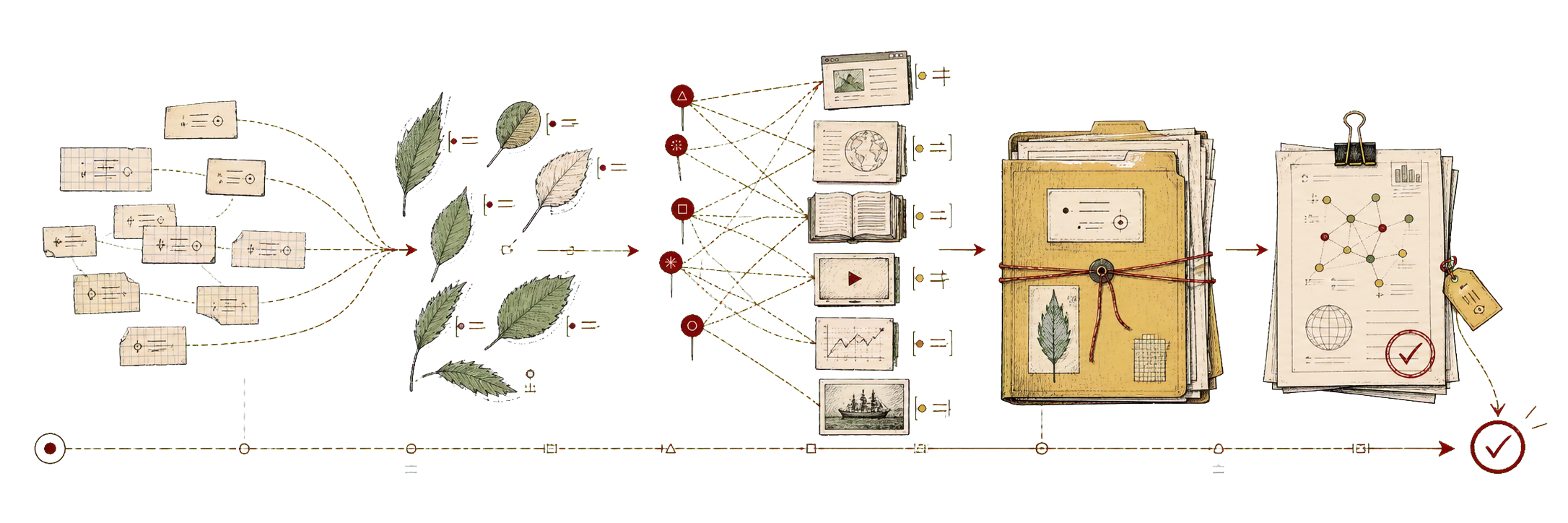
The first real lesson was that deep research is not “more web search.” It is a loop.
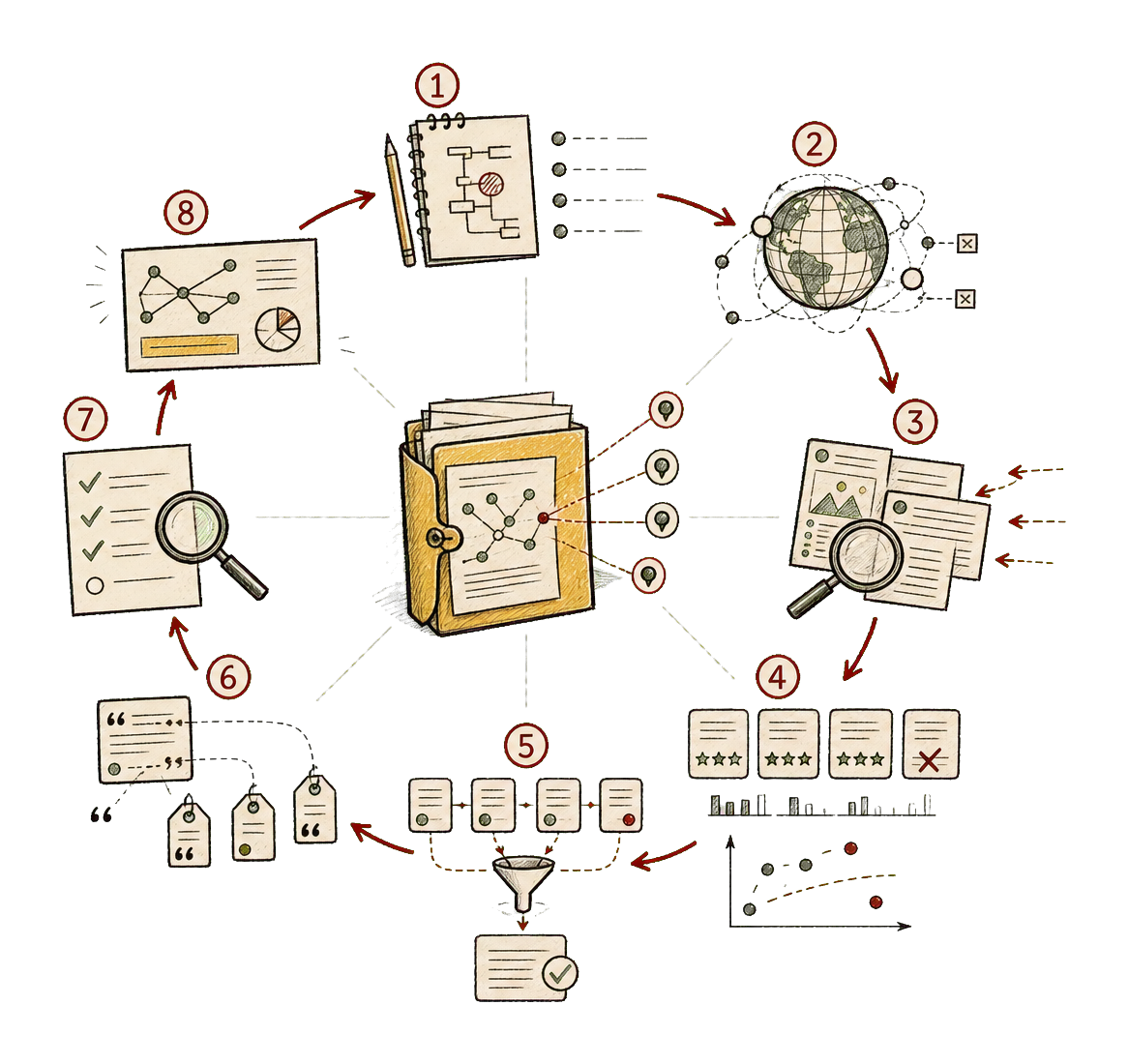
Plan the question. Expand it into sub-questions. Decide which kinds of sources would actually count. Search broadly. Prefer primary sources when they exist. Fetch readable pages. Fall back to rendered browser extraction when the raw page is thin or JavaScript-shaped. Score sources. Deduplicate the same recycled claim appearing in different coats. Preserve failed fetches instead of pretending the web was cooperative. Build a dossier. Ask a reviewer to challenge the coverage. Then write the report from the curated evidence, not from the glow of having done many tool calls.
That distinction matters because tool activity is cheap theatre. An agent can perform busyness with beautiful endurance. It can open pages, summarize pages, open more pages, summarize those pages, and still never notice that every source is quoting the same original announcement. The useful version has to treat source provenance as part of the product, not as a debugging trace left behind for the unusually nosy.
This is where the implementation began to clarify itself.
Atlas already had the right architectural pieces: thread-level ownership, intent routing, subagent roles, workflow durability, web search, readable fetch, citation tooling, Browser Run, AI Search, and transcript rendering for live research state. The wrong move would have been to build a separate research service with its own invented personalities and then spend the rest of the year reconciling it with the real product. The better move was to extend the seams that already existed.
The parent thread owns the relationship with the user. Explorer agents go out to search, fetch, read, cite, and return grounded findings. Fast workers do bounded mechanical work: query expansion, URL dedupe, passage clustering, source classification, citation normalization. A reviewer audits coverage and unsupported claims. A worker enters only when the research task genuinely needs code, data analysis, exports, or some artifact with a clear boundary.
That sounds like an org chart until it runs. Then it becomes a way to keep the work honest.
Research agents are unusually prone to becoming fluent from weak evidence. They read a mediocre source, absorb its posture, and then write as though the claim has been pressure-tested. The fix is not to forbid weak sources, because sometimes weak sources are the clue that leads to the strong one. The fix is to prevent weak sources from becoming the backbone of the answer.
So the source model became part of the work: official pages, primary docs, standards, filings, papers, and vendor help centers first; mirrors and recycled summaries only when the better trail runs cold. If an official page blocks direct capture, say so. Try markdown. Try rendered extraction. If all that fails and the only official evidence is a search snippet, preserve it as weaker evidence rather than laundering it into the same confidence tier as a full read. This is fussy, but the fussiness is the feature.
The final report surface mattered just as much. A research answer should not end with a huge visible bibliography wall that shoves the useful memo off the screen. The report should read like a document: polished prose, inline numeric citations, previews on hover or tap, and a source inspector available when the reader wants to audit the trail. The sources should be close enough to trust and quiet enough that the answer remains readable.
That is a product judgment, not just a rendering choice. If the citation system is too hidden, the answer feels magical in the bad way. If it is too loud, the answer becomes a parts bin. The right shape is a memo with inspectable seams.
The most useful part, in practice, is the way Deep Research changes the agent’s temperament. A normal turn tends to optimize for answering. A research turn optimizes for coverage, contradiction, and grounded synthesis. It makes the agent slower in a way that feels civilized. It stops early when returns diminish, but it reserves time for verification and writing because a perfect evidence pile with a rushed final answer is still a bad product.
There is also a surprisingly human benefit to visible progress. Watching a research run move through planning, discovery, acquisition, review, and synthesis changes how one relates to the answer. It is not just that the user sees the machine working. It is that the user can tell what kind of work is happening, and can interrupt or refine while the run is still alive.
That is the next important surface: editable plan preview, source-scope controls, refine-while-running, trusted-sites-only mode, attached-sources-only mode, and a dossier inspector where sources can be included, excluded, or challenged. Without those controls, Deep Research is a clever batch job. With them, it becomes a research conversation.
The feature is deceptively simple to describe: ask the agent to search the web widely and produce a broad, grounded perspective from many sources. The real implementation is less glamorous and more useful. It is about source discipline, durable evidence, citation UX, phase-level orchestration, and a reviewer pass that has permission to be unpleasant before the answer reaches the reader.
That is what I like about it. It gives the agent a better ritual.
Not “find me something and sound clever about it.” Not “produce a wall of links and call the wall confidence.” The better instruction is slower and more exacting: map the question, collect the evidence, notice what is weak, make the case, and leave enough of the route visible that someone else can follow it without trusting the weather report.
Field note
Deep Research is useful because it changes the default posture from answer-first to evidence-first. It makes the agent search wider, read harder, cite more carefully, and think before it writes, which is often the difference between a response that is plausible and a response that can survive being looked at twice.